
pwn差缺补漏-got.plt-rop-pwntools-延迟绑定啥都有
0-Preview
今天(10.6,虽然写完已经第二天了)就不盲目刷题了,把之前没搞懂的问题和没学的东西都处理一下,为明天学堆做准备。
截止目前,我还是有很多地方学的不是很仔细。
1、ROPgadget 是干什么用的,原理是啥。
2、got 表是啥,和 plt啥关系。
3、pwntools一些函数作用原理:symbols
4、bss段是啥
5、调试工具
1-基本ROP
由于NX开启不能在栈上执行shellcode,我们可以在栈上布置一系列的返回地址与参数,这样可以进行多次的函数调用,通过函数尾部的ret语句控制程序的流程,而用程序中的一些pop/ret的代码块(称之为gadget)来平衡堆栈。
其完成的事情无非就是放上/bin/sh,覆盖程序中某个函数的GOT为system的,然后ret到那个函数的plt就可以触发system('/bin/sh')。由于是利用ret指令的exploit,所以叫Return-Oriented Programming。(如果没有开启ASLR,可以直接使用ret2libc技术)
gadgets 就是以 ret 结尾的指令序列,通过这些指令序列,我们可以修改某些地址的内容,方便控制程序的执行流程。
之所以称之为 ROP,是因为核心在于利用了指令集中的 ret 指令,改变了指令流的执行顺序。ROP 攻击一般得满足如下条件:
- 程序存在溢出,并且可以控制返回地址。
- 可以找到满足条件的 gadgets 以及相应 gadgets 的地址。
2-bss段
bss段通常是指用来存放程序中未初始化的全局变量的一块内存区域,
一般在初始化时bss 段部分将会清零。bss段属于静态内存分配,即程序一开始就将其清零了。
比如,在C语言之类的程序编译完成之后,已初始化的全局变量保存在.data 段中,未初始化的全局变量保存在.bss 段中。
text和data段都在可执行文件中(在嵌入式系统里一般是固化在镜像文件中),由系统从可执行文件中加载;
而bss段不在可执行文件中,由系统初始化。
bss段:
**bss段(bss segment)**通常是指用来存放程序中未初始化的全局变量的一块内存区域。 bss是英文Block Started by Symbol的简称。
bss段属于静态内存分配。data段:
**数据段(data segment)**通常是指用来存放程序中已初始化的全局变量的一块内存区域。 数据段属于静态内存分配。
text段:
**代码段(code segment/text segment)**通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读(某些架构也允许代码段为可写,即允许修改程序)。
在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。堆(heap):
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。
当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张); 当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。栈(stack):
栈又称堆栈,是用户存放程序临时创建的局部变量,
也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中
除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。
什么意思呢?
我还是换成人话讲一下吧。
IDA 分析程序时候,会见到很多变量,有的变量没有初始化。例如:
1 | C |
起初s是存在bss段里面的,因为他并没有初始化。
这时候如果bss段有执行权限的话,我们就可以写入shellcode。
使用下面的命令可以查看程序的bss段具体地址,和查询执行权限:
1 | BASH |
3-got-plt
要说这个,就要提到 Linux的动态链接了。
3.1-Linux动态链接
用人话说一下就是:
代码编译成程序的时候,要经过链接外部资源。你代码中的
printf()实际上也是一个函数,他的代码存在另一个地方( glibc 动态库)。想要程序能正常运行,就必须要将外部的这部分代码也加进来。
静态链接就是,直接从库里面把函数扒出来,加到代码里进行编译。
动态链接不同,他只用一些符号代替函数,当需要调用他的时候,他再去库里面现找。
还不理解?👴给你小刀拉屁股(开开眼:
看着这张图,这叫静态链接:
再看这张图,这就叫动态链接:
图片

3.2-PLT&GOT
linux下的动态链接是通过PLT&GOT来实现的,这里做一个实验,通过这个实验来理解:
使用如下源代码 test.c:
1 | C |
依次使用下列命令进行编译:
1 | BASH |
参数详解:
-c:只激活预处理,编译,和汇编,也就是他只把程序做成obj文件
-o:制定目标名称, 默认的时候, gcc 编译出来的文件是 a.out, 很难听, 改掉它, 哈哈。
-g:只是编译器,在编译的时候,产生调试信息。
-Wall:生成所有警告信息。
-no-pie: 关闭 PIE 方便我们调试,要不然出来反汇编全是下图这样的 寄存器而不是具体地址
-M intel:这是 objdump 的参数,也写在这里。chumen👴说要看intel风格的汇编,另一个风 格就是下图那些,寄存器前面会加 % 等一些奇怪的东西。
通过 objdump -d test.o 可以查看反汇编:
printf() 和函数是在 glibc 动态库里面的,只有当程序运行起来的时候才能确定地址,所以此时的 printf() 函数先用 fc ff ff ff 也就是有符号数的 -4 代替。
运行时进行重定位是无法修改代码段的,只能将 printf 重定位到数据段。
那么是怎么找到真是地址的呢?
已经编译好的程序,调用 printf 的时候,链接器会额外生成一小段代码,通过这段代码来获取 printf() 的地址,像下面这样,进行链接的时候只需要对printf_stub() 进行重定位操作就可以。
1 | CODE |
总结一下:动态链接每个函数需要两个东西:
1、用来存放外部函数地址的数据段
2、用来获取数据段记录的外部函数地址的代码
刚好有两个表实现了这两个要求,就是我们搞不懂的 got 和 plt:
存放外部的函数地址的数据表称为全局偏移表(GOT, Global Offset Table),
存放额外代码的表称为程序链接表(PLT,Procedure Link Table)
讲人话环节:
编译好的程序里面并没有 printf 的代码,需要去外部找。但是动态链接是不能提前知道真实地址的。然后链接器会生成一段代码用来获取 printf 的地址。要实现这个功能,就需要一个存储这些寻址代码的数据表,还需要一个存储着所有外置函数地址的表。他们分别是 PLT 和 GOT。
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址
那我们可以发现,在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较麻烦的,为此,linux 引入了延迟绑定机制
3.3-延迟绑定
只有动态库函数在被调用时,才会地址解析和重定位工作,为此可以使用类似这样的代码来实现:
1 | CODE |
说明一下这段代码工作流程,一开始,printf@got 是 lookup_printf 函数的地址,这个函数用来寻找 printf() 的地址,然后写入 printf@got,lookup_printf 执行完成后会返回到 address_good,这样再 jmp 的话就可以直接跳到printf 来执行了
讲人话环节
为了节省资源,一开始是不进行重定向的,太多函数太麻烦。而是执行上述函数中的
lookup_printf先查找到printf的地址,然后写入到*printf@got。当程序执行到需要用printf函数的时候,才回去执行jmp *printf@got。这样设计能节省资源如果不知道 printf 的地址,就去找一下,知道的话就直接去 jmp 执行 printf 了
“ 找 ” 地址的实现原理
通过 objdump -M intel -d test > test.asm 可以看到其中 plt 表项有三条指令:
1 | CODE |
其中除第一个表项以外,plt 表的第一条都是跳转到对应的 got 表项,而 got 表项的内容我们可以通过 gdb 来看一下,如果函数还没有执行的时候,这里的地址是对应 plt 表项的下一条命令,即 push 0x0
我们来调试看一下这些地址里面都存的啥:
先 gdb test 然后 b main,再 run, 再 x/x jmp的那个地址 就可以看了

很明显了,首先跳到 got 地址,got地址中存储着,公共plt地址,公共plt跳转到 lookup功能的地址。
Look up 实现的代码:
1 | CODE |
然后就是第一个plt表项的内容:
1 | CODE |
跳转过去的地址是:
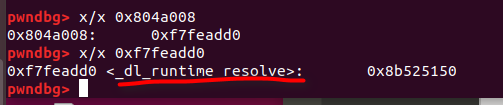
_dl_runtime_resolve的作用就是查找 printf 的地址。
3.4-总结and疑问
程序如果调用的函数没有被调用过,那么我们想要调用他,就要经过这几步:
xxx@plt -> xxx@got -> xxx@pl -> 公共@plt -> _dl_runtime_resolve
那么问题也就来了:
- _dl_runtime_resolve 是怎么知道要查找 printf 函数的
- _dl_runtime_resolve 找到 printf 函数地址之后,它怎么知道回填到哪个 GOT 表项
Answer-1:
在 xxx@plt 中,我们在 jmp 之前 push 了一个参数,每个 xxx@plt 的 push 的操作数都不一样,那个参数就相当于函数的 id,告诉了 _dl_runtime_resolve 要去找哪一个函数的地址
在 elf 文件中 .rel.plt 保存了重定位表的信息,使用
readelf -r test命令可以查看 test 可执行文件中的重定位信息
我直接从大佬博客找了个中文版界面,对着看一下:

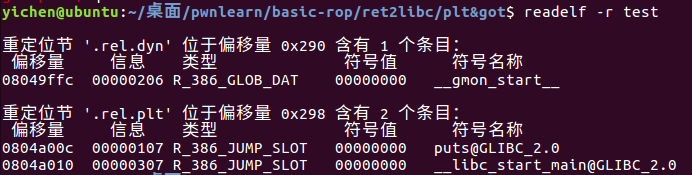
看大佬博客说的是,push进去的操作数是和这个偏移量相同的。
但是我实调结果却是不一样的。
这个问题留着以后研究。
Answer-2:
看 .rel.plt 的位置就对应着 xxx@plt 里 jmp 的地址
在 i386 架构下,除了每个函数占用一个 GOT 表项外,GOT 表项还保留了3个公共表项,也即 got 的前3项,分别保存:
got [0]: 本 ELF 动态段 (.dynamic 段)的装载地址
got [1]:本 ELF 的 link_map 数据结构描述符地址
got [2]:_dl_runtime_resolve 函数的地址
动态链接器在加载完 ELF 之后,都会将这3地址写到 GOT 表的前3项
3.5-完整流程总结
第一次调用:
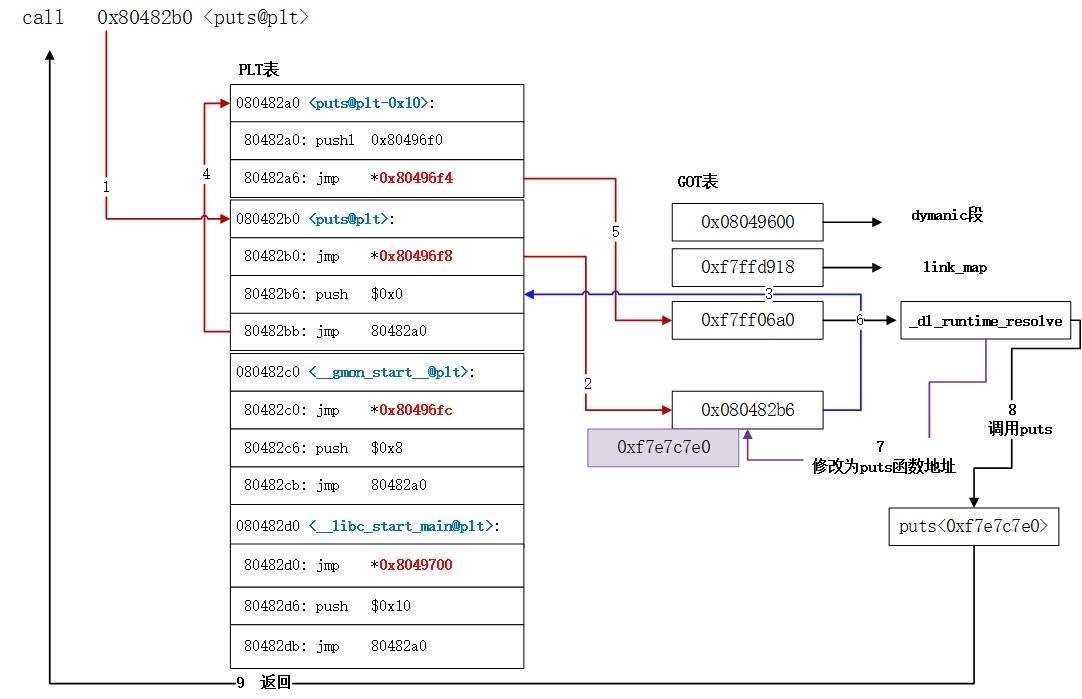
第二次调用:

4-pwntools
4.1-pwntools常用模块:
- asm : 汇编与反汇编,支持x86/x64/arm/mips/powerpc等基本上所有的主流平台
- dynelf : 用于远程符号泄漏,需要提供leak方法
- elf : 对elf文件进行操作
- gdb : 配合gdb进行调试
- memleak : 用于内存泄漏
- shellcraft : shellcode的生成器
- tubes : 包括tubes.sock, tubes.process, tubes.ssh, tubes.serialtube,分别适用于不同场景的PIPE
- utils : 一些实用的小功能,例如CRC计算,cyclic pattern等
除了我们常用的交互模块,也可以使用listen来开启一个本地的监听端口:
1 | PYTHON |
4.2-交互函数:
- interactive() : 直接进行交互,相当于回到shell的模式,在取得shell之后使用
- recv(numb=4096, timeout=default) : 接收指定字节
- recvall() : 一直接收直到EOF
- recvline(keepends=True) : 接收一行,keepends为是否保留行尾的\n
- recvuntil(delims, drop=False) : 一直读到delims的pattern出现为止
- recvrepeat(timeout=default) : 持续接受直到EOF或timeout
- send(data) : 发送数据
- sendline(data) : 发送一行数据,相当于在数据末尾加\n
4.3-汇编反汇编
使用asm来进行汇编:
1 | PYTHON |
注意,asm需要binutils中的as工具辅助,如果是不同于本机平台的其他平台的汇编,例如在我的x86机器上进行mips的汇编就会出现as工具未找到的情况,这时候需要安装其他平台的cross-binutils。
可以使用context来指定cpu类型以及操作系统:
1 | PYTHON |
使用disasm进行反汇编:
1 | PYTHON |
4.4-Shellcode生成器
使用 shellcraft 可以生成对应的架构的shellcode代码,直接使用链式调用的方法就可以得到
1 | PYTHON |
如上所示,如果需要在64位的Linux上执行/bin/sh就可以使用shellcraft.amd64.linux.sh(),配合asm函数就能够得到最终的pyaload了。
除了直接执行sh之外,还可以进行其它的一些常用操作例如提权、反向连接等等。
4.5-ELF文件操作
- asm(address, assembly) : 在指定地址进行汇编
- bss(offset) : 返回bss段的位置,offset是偏移值
- checksec() : 对elf进行一些安全保护检查,例如NX, PIE等。
- disasm(address, n_bytes) : 在指定位置进行n_bytes个字节的反汇编
- offset_to_vaddr(offset) : 将文件中的偏移offset转换成虚拟地址VMA
- vaddr_to_offset(address) : 与上面的函数作用相反
- read(address, count) : 在address(VMA)位置读取count个字节
- write(address, data) : 在address(VMA)位置写入data
- section(name) : dump出指定section的数据
elf模块提供了一种便捷的方法能够迅速的得到文件内函数的地址,plt位置以及got表的位置。
1 | PYTHON |
甚至可以修改一个ELF的代码
1 | PYTHON |
4.6-ROP链生成器
ROP模块的作用,就是自动地寻找程序里的gadget,自动在栈上部署对应的参数。
1 | PYTHON |
使用ROP(elf)来产生一个rop的对象,这时rop链还是空的,需要在其中添加函数。
因为ROP对象实现了__getattr__的功能,可以直接通过func call的形式来添加函数,rop.read(0, elf.bss(0x80))实际相当于rop.call('read', (0, elf.bss(0x80)))。 通过多次添加函数调用,最后使用str将整个rop chain dump出来就可以了。
- call(resolvable, arguments=()) : 添加一个调用,resolvable可以是一个符号,也可以是一个int型地址,注意后面的参数必须是元组否则会报错,即使只有一个参数也要写成元组的形式(在后面加上一个逗号)
- chain() : 返回当前的字节序列,即payload
- dump() : 直观地展示出当前的rop chain
- raw() : 在rop chain中加上一个整数或字符串
- search(move=0, regs=None, order=’size’) : 按特定条件搜索gadget,没仔细研究过
- unresolve(value) : 给出一个地址,反解析出符号
4.7-数据处理
对于整数的pack与数据的unpack,可以使用p32,p64,u32,u64这些函数,分别对应着32位和64位的整数。
5-调试工具
基础的就是gdb了,但是功能太少,用起来麻烦。
后来就用了peda插件。
再后来,发现pwndbg更香,果断抛弃 peda。
Pwndbg exists not only to replace all of its predecessors
大致意思就是:我 Pwndbg 存在的最基本意义就是为了打败所有的前辈
6-👴的bb赖赖
太难了!
本来我以为今天差缺补漏的任务是这几天最轻松的,结果写了五千多字。
一头扎进来,搞到了第二天;

这算是有史以来写的最长的一篇博客了。
明天就要开始学堆了,又是一个难点,脱发ing。
chumen👴又教会了我新的姿势:看文件字节码
类似于校验位那种,可以从字节码看出来这个程序开了pie啊,或者啥信息。
tql!
十二点了,但是好习惯不能断,得去健身了。
目标是近战黑阔冲冲冲!



