爬虫序章-爬取百度并提取信息
Python-爬虫序章
出了道re题,当了一早上客服,好在终于有人解出来了(未提示)。
打开知识星球发现学长发布了作业,让学python爬取东西。
突发奇想:我要当 python👴 , 我要爬🐍图!!!
要求
使用 requests + BeautifulSoup 两个库。编写脚本,抓取 百度主页 。
运行结果 打印 出百度主页的 “ 意见反馈 ” 四个 汉字。
🌟代码中不允许出现汉字。
🌟两个库都需要用到。
准备
!!!看仔细!!!
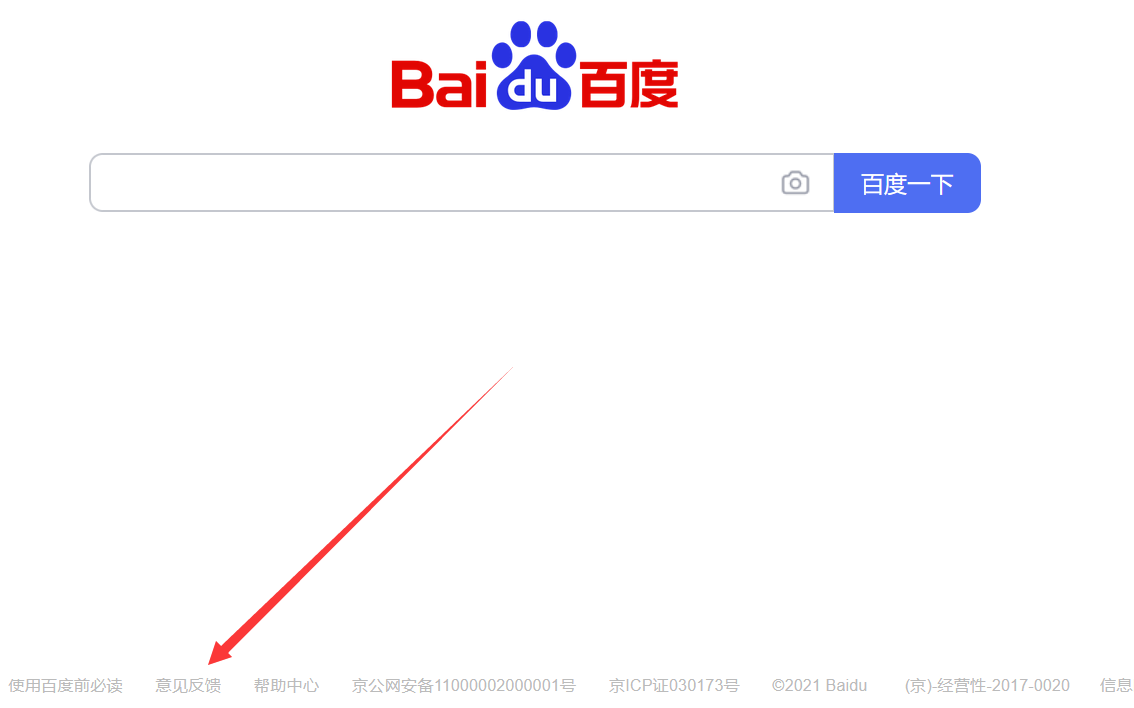
要爬取的东西就是箭头指向的那个,小小的——意见反馈。
首先分析一下问题;整体思路要清楚,即便没有学过爬虫但是依靠编程基础和思维,也可以想到步骤;
我的第一印象如下:
⭐️request 用来获取百度网页信息;
⭐️对获得的信息进行检索匹配;
⭐️输出
不过有一个很明显的问题,要求代码中不能出现中文,意思是不能直接进行字符串匹配然后输出;然后诞生了一下思路:
⭐️把中文转换成其他编码,绕过学长定的要求。(不建议)
比如 base64 啥的。
⭐️F12 查看网页源码,找到 意见反馈 这些按钮不同的地方,匹配输出;
操作
首先安装上面提到的两个库,其中 BeautifulSoup 提示安装失败,百度找了一圈发现整合到bs4
里面去了;
1 | PYTHON |
引用就和其他的整合类一样,具体看下面代码;

所以要找到我们要爬取的信息,需要这样写:
1 | PYTHON |
最初我发现 requests.get() 的返回值类型特殊,不能使用 find 查找。

所以暂时先用 urlopen 来读取网页信息。完成代码如下:
1 | PYTHON |
写到这里,算是验证了我的思路是对的,实际上已经不用往下继续了,但是脑子一热,不行,这不符合我想当 Python 👴 的气质。

继续干!
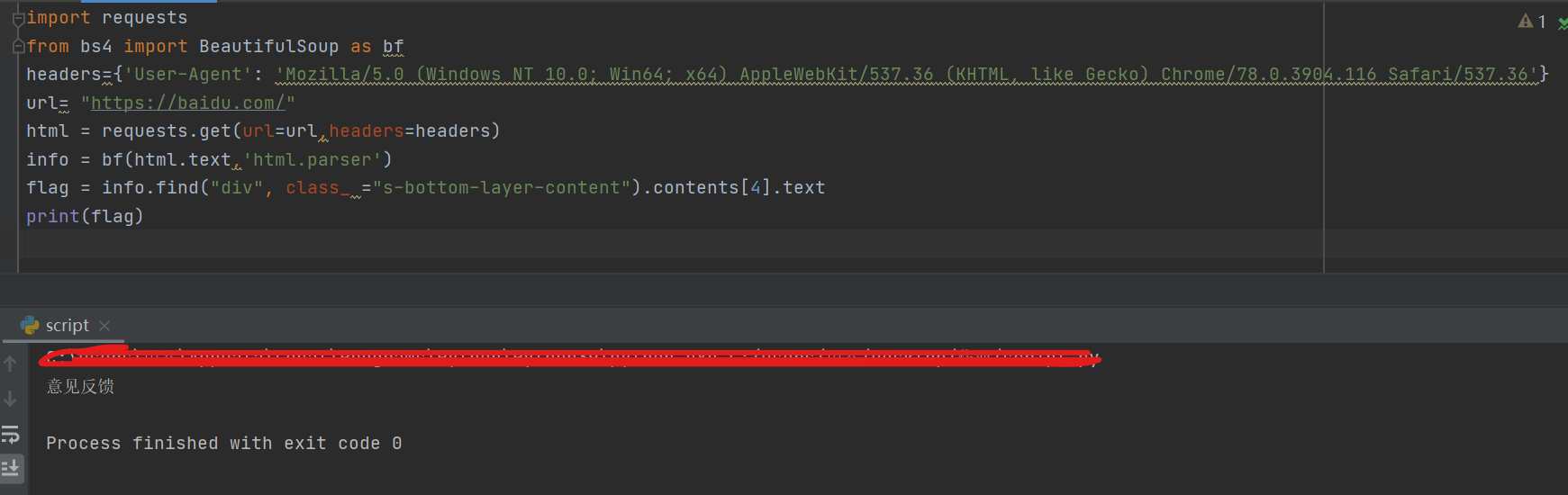
接下来就是解决的问题就是 request.get() 得到的数据怎么进行处理了。
艹了,《hui气》;
👴一直以为是get得到的数据类型不支持 BeautifulSoup 结果是因为这句话出现的问题:
info = bf(html.read(),‘html.parser’) #就是上面 urlopen 的代码
意思是 urlopen 不支持 BeautifulSoup 需要转换,而 request.get() 压根不用转换,直接导入就行。
1 | PYTHON |
[ ](http://image.shangu127.top/image/image/ctf/屏幕截图 2021-05-31 200821.png)
](http://image.shangu127.top/image/image/ctf/屏幕截图 2021-05-31 200821.png)
爬虫真好玩!
学会了两个包的使用,真好!
嘉宾和赞助
本篇文章由两位特邀大佬帮助下完成。
正在添加评论系统,欢迎孤立我。进度:0/100;